
7·
5 days agoHamburg court. Notorious court for such digital rights cases.
Hamburg court. Notorious court for such digital rights cases.
The lawsuit is not about downloading, but about enabling circumventing protections.
By your analogy, it’s not about the shops selling kitchen knives, but hosting a side door to a protected weapons/knifes shop.
(I hate analogies. In general. But wtf is that analogy now that we included more context?)
lower and higher court are different people
What logic do you mean?
Images are typically not encrypted with protection measures [in transit].
they can and will take it away
The example you give is more “have to take down because of legal requirements” than “can and will”.
If you downloaded it you still have it though. Which is the big difference.
Whoa, I’m getting dizzy while scrolling. That background…
Depending on what you want to scape, that’s a lot of overkill and overcomplication. Full website testing frameworks may not be necessary to scrape. Python with it’s tooling and package management may not be necessary.
I’ve recently extracted and downloaded stuff via Nushell.
document.querySelectorAll()For me, my command line terminal and scripting language of choice is Nushell:
let $html = http get 'https://example.org/'
let $meta = $html | query web --query '#infobox .title, #infobox .tags' | | { title: $in.0.0 tags: $in.1.0 }
let $content = $html | query web --query 'main img' --attribute data-src
$meta | save meta.json
or
1..30 | each {|x| http get $'https://example.org/img/($x).jpg' | save $'($x).jpg'; sleep 100ms }
Depending on the tools you use, it’ll be quite similar or very different.
Selenium is an entire web-browser driver meaning it does a lot more and has a more extensive interface because of it; and you can talk to it through different interfaces and languages.
You don’t even need a VPN to use a different DNS server.
Injecting a malicious undisclosed firmware/software update. Very private and secure. /s
That’s bullshit. There’s no reason to limit or target a specific or non-maximum CPU core usage.
That would only make sense to evade hardware faults or cooling issues. Never as a general guideline.
YouTube channels can be terminated for both repeated copyright infringement and community guideline violations. In these cases, revenues are often withheld as well. It’s possible, however, that linked AdSense accounts are treated differently.
AdSense policies can be confusing, but based on additional information provided by Google’s AI, YouTube copyright bans are most likely to result in AdSense terminations too.
This is the first time I read of an AI as a source / AI being a source for an article.
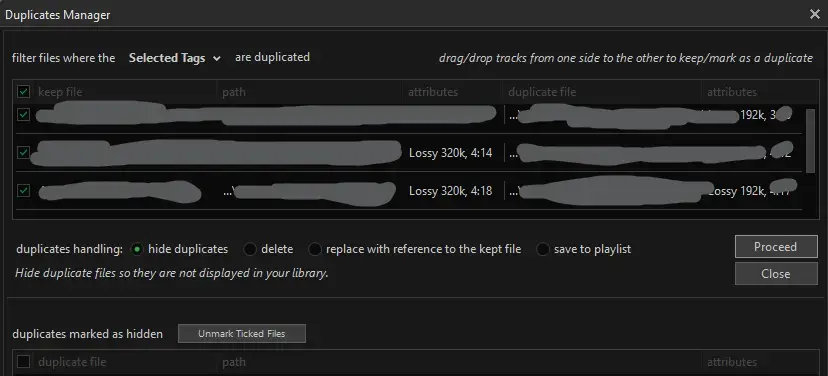
MusicBee has Tools -> Manage Duplicates
For reference, the source file is background.js
URLs at the top, init calls at the bottom, and above that the event registering stuff (tab nav and nav).
Notably, 5.0.1 was released three days ago. So a fix is available.
The first patched release is version 5.0.1, released 2 days ago.
With Ollama you can install and use various free AI models.
What do you mean by Grammarly costs a lot of money? It has a free tier. Which is quite generous.
Seems strange that the dev seems to be keeping quiet on this, no?
Which one? The repo owner certainly doesn’t seem very active in general.
but “The tittle says it all” /s
{kind=link}
I don’t think that qualifies as “protection” of copyrighted content before law?
Some YouTube videos are protected like that, others not. The lawsuit is about those being circumvented. It is NOT about SSL or circumventing SSL.
An equivalent would be a copyright protection on images. Not SSL.
Forgive me if I am lacking the correct term for it.